By Dr (Professor) Surjit Singh Bhatti , (surjitsinghbhatti@gmail.com, drssbhatti.ca)
Modern Artificial Intelligence (AI) can be traced back to a British polymath named Alan Turing who explored the mathematical probability of an Intelligent Machine – one that can use reason and available data/information to make decisions. Exactly as humans do. His 1950 paper titled “Computing Machinery and Intelligence” delved deeper into this concept and scoped the concept of building such a machine and also to test its intelligence. AI as a branch of science could not take off since early computers could not store commands. They could only execute command in real time. AI and its associated fields (Machine Learning, Expert Systems and others) passed through many hoops in the later half of the last century but by 1997, the reigning world chess champion and grand master Gary Kasparov was defeated by IBM’s Deep Blue – a computer program that excelled at playing chess.
Machine Learning (ML) concept can be traced back to Walter Pitts and Warren McCulloch who presented the first mathematical model of neural networks (NN) in their paper titled, “A Logical Calculus of the Ideas Immanent in Nervous Activity”. Machine learning algorithms aim to optimize the performance of a certain task by using examples and/or experience. Human beings can make decisions using only a few variables at a time. Computers, however, can make decisions on millions of variables at a time and are not limited in memory. This technique, therefore, is particularly useful when there are a very large number of variables which have to be considered. It has applications in almost all fields of activity, ranging from sciences, technology and medicine, to business, economics and politics. This involves knowledge of two processes, Data Mining and Machine Learning. This blog gives a basic introduction to these two.
Data Mining (DM) is the collection of all relevant data useful for decision-making in a problem, based on a certain (minimum) number of relevant variables. It is also known as Knowledge Discovery in Databases. It involves the following steps.
- Data Cleaning, whose purpose is to remove all inconsistent data
- Data Integration, which combines all data from multiple sources
- Data Selection, is done to enlist data for analysis of task at hand
- Data Transformation, is needed to change data into 1 and 0 form
- Knowledge Discovery, is made by intelligent pattern recognition
- Pattern Evaluation, is done to identify truly interesting patterns
- Knowledge Presentation, is to present the ‘mined’ results to users
Anomalies exist in many large data collections. These are called outliers, noise, or deviations. Detection of Anomalies is a must and a process undertaken during Data Mining (DM) itself. It is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data. Typically, the anomalous items represent an issue, such as bank fraud, a structural defect, medical problems or errors in a text.
MACHINE LEARNING (ML)
Machine Learning is the procedure followed by humans to teach machines to take decisions using the large amount of data mined in the above process. It may make use of Artificial Intelligence (AI), Statistics and Artificial Neural Networks (ANN), to provide the systems the ability to automatically learn and improve from experience, without being explicitly programmed. It focuses on the development of computer programs that can access data and use it to learn for themselves. Artificial Intelligence is the name given to any technique that enables computers to mimic human intelligence to arrive at the best decisions.
Performing machine learning involves creating a ‘model’, which is trained on some ‘training data s and then can process additional data to make predictions. Various types of models have been used for ML systems. An example is the Bayesian network. Rain influences whether a sprinkler is activated, and both rain and the sprinkler influence whether the grass is wet.
Machine Learning Algorithm and Models
ML Algorithm is a program that is implemented in machine-readable code and is run on data sets. It is the hypothesis set that is selected in the beginning, before training starts with real-world data.
ML Models give output by algorithms and have model data and a prediction algorithm. It is a mathematical representation of a real-world process. We need to provide a large Training (data) Set to ML algorithm to learn from, and build a model. To validate it, we evaluate its performance using a smaller Testing (data) Set. These are created by splitting the available data in two parts.
Machine L earning Processing involves the following minimum requirements to be satisfied.
Linear Regression Algorithm, a program has to be chosen such that it gives us a set of functions with similar characteristics from which we can choose the one that fits the most in the training data set.
Classification is the next step wherein categorization of the data into pre-defined classes is done. (For example, an email can be classified as spam, not-spam, junk, important, starred, or personal).
A Target has to be fixed to be defined for output of the individual classes such that input variables may be mapped correctly (in classification) on the output value range (as in a regression problem).
Features (also known as attributes or dimensions) are required to be noted beforehand for the individual variables that act as independent inputs, to make correct predictions. New features can be obtained from the old features, and one column of data is set as one independent new feature.
Input features are the algorithms from which the system learns, to predict the desired output.
Output (Label or Target feature) is what is being predicted. (Labels are put on the final output).
Sampling is done by randomly selecting a certain percentage of the data, instead of entire data set.
Feature Analysis is done finally to decide which of the input features are contributing to prediction of the output feature. This is done in order to exclude irrelevant features so as to simplify the process. This fixes data quality issues and makes it easier for algorithms to learn from it.
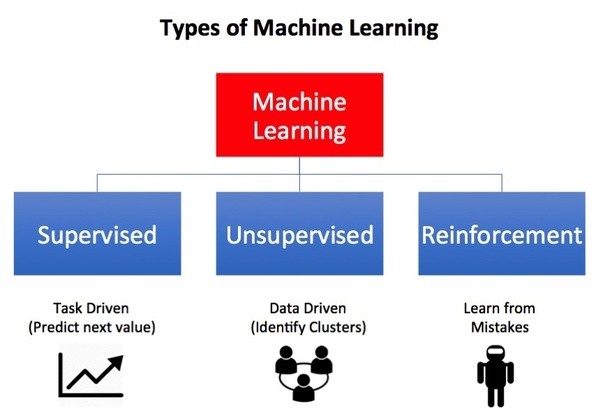
Types of Machine Learning (M L)
M L algorithms provide a type of automatic programming process whereas ML models represent the program. It is more effective to help the machine develop its own algorithm, rather than having human programmers specify every needed step. This is achieved by one of the following methods, depending upon the nature of the problem and feedback available to the learning system.
Supervised Learning: The computer is presented with example inputs and their desired outputs and the goal is to learn a rule that maps inputs to outputs. The learning algorithms build a mathematical model of a set of data that contains both the inputs and the desired outputs. This model uses Training Data, and consists of a set of training examples. Each training example has one or more inputs and the desired output, also known as a supervisory signal. An algorithm that improves the accuracy of its outputs or predictions over time is said to have ‘learned’ to perform that task.
Unsupervised Learning: Here learning algorithm is left on its own to find structures in its input, so that it is a goal to discover the hidden patterns (if any) in the data. Learning algorithms take a set of data that contains only inputs, and find a structure, like grouping or clustering of data points. The algorithms, therefore, learn from test data that has not been labeled, classified, or categorized. Instead of responding to feedback, here learning algorithms identify commonalities in the data and react based on their presence or absence in the data. It finds hidden patterns in input data.
Reinforcement Learning: In this case the program interacts with a given dynamic environment to perform a certain goal (such as driving a vehicle or playing a game against an opponent). The program is provided feedback analogous to desired results, which it tries to maximize. It is concerned with how to take actions in this environment so as to maximize the result. Due to its generality, this has applications in many disciplines. Here learning algorithms do not assume knowledge of an exact mathematical model and are used when exact models are not feasible.
Data Analysis in Machine Learning
Data Analysis may be done in many formats and representations, generally the following.
- Tabular Data, Multimedia Data (images, videos and audio), called Computer Vision
2. Text Data (text from documents, chat, and language processing) and
3. Time Series Data (Weather data, Stock data, Time-related or sequence data).
Data Analysis involves the following important steps.
Transformation of data converts it into different formats and assigns numbers to their variables.
Simplification of features is undertaken by splitting an inconvenient parameter into many features.
Missing values treatment is done by deleting missing rows or by filling missing values by using a constant or mean or median values of the features or by using their most probable values.
Checking for Imbalanced data is the next step. For instance, in identifying credit fraud, we may get only 10% data which has fraudulent transactions, but 90% of it is good or reliable data. We can say: 10% bad vs. 90% good data is an imbalanced data, but 40% vs 60% may not be.
Data sampling is done by selecting about 15% to 20% of the good transactions. But if it is imbalanced because of missing data, we can replace missing data with the averaged values.
Making Data-sets and Building a Model in Machine Learning
A larger portion of data, called Training Set is used as a sample which is intended to build a Model and the smaller portion of data, called Testing Set is reserved for testing that model. Data is split to evaluate the model’s performance. A good model should perform well on any new and unseen data.
Sampling technique, such as K-fold cross-validation, is commonly used. Here we partition the data into (k) different sets. We may choose k =10, and use sets 1 to 9 to train, and use set 10 to test. Next, we use sets 1 to 8 and 10 to train and use 9 to test. We repeat the process until all sets have been used to test. This repeated splitting of mined data is done to test the Model completely.
DEEP LEARNING (DL)
This is yet another technique which is inspired by the way the human brain filters information through many layers using biological neural networks. This technique employs Artificial Neural Networks (ANN) to imitate the functioning of the human brain and filters the inputs through many more layers, and is more accurate than Machine Learning (ML). It is used in image and speech recognition processes, among many other applications. Recently, researchers at Johannes Kepler University report use of AI to improve thermal imaging camera searches of people lost in the woods, in a paper in Nature (Machine Intelligence).
Comparison of DL and ML
Machine Learning (ML) is a subset of Artificial Intelligence that includes techniques that enable machines to improve at tasks with experience. It also includes DL as a special subset of ML.
Deep Learning (DL) includes ANN’s that permit a machine to train itself to perform the required task. The algorithm structure for DL is more complex (or more layered) and the data as well as hardware requirements are also high compared to ML. This makes the execution time longer. However, the processing is similar in both cases.
Text Mining (or Text Analytics) is an AI technology that uses Natural Language Processing (NLP) to transform the free (unstructured) text in documents and databases into normalized, structured data, suitable for analysis or to drive ML algorithms. It is the process of deriving high-quality information from text and involves the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources.
Text Mining (TM) is the process of examining very large collections of written information to discover relevant data by suitably transforming the original text. It accomplishes this transformation by using NLP and some other techniques. The goal is to discover relevant data that is unknown and hidden in the huge collection of other information.
Text Mining (TM) and Natural Language Processing (NLP)
Natural Language Processing (NLP) is a component of TM that performs a kind of linguistic analysis that helps a machine to read the text. It deciphers ambiguities in the language, removes them and achieves automatic summarization in speech, natural language understanding and recognition. The NLP has a consistent knowledge base such as a detailed thesaurus, a lexicon of words, a data set for linguistic and grammatical rules. The software process runs in the background of common applications such as the personal assistant in smartphones, translation software and in self-service phone banking applications.
It is impossible for one individual to read all of the information and identify what is most important. Here text mining applications using NLP do this job easily for us. More than a search tool that returns a list of sources that match our request, text mining tools go further to give us detailed information about the text itself and reveals patterns across the millions of documents in the data set. A common applications is social media monitoring, where an analysis is performed on a pool of user-generated content to understand their awareness related to a topic.
Some Recent Applications
Drug discovery and development are long, complex, and arduous processes, and depend on numerous factors. ML helps in decision-making with abundant data. It is applied in drug discovery, target validation, identification of prognostic biomarkers and analysis of digital pathology data in clinical trials, making accurate predictions. Decision-making speeds up the processes and reduces failure rates. Normally, it takes about 10 years and costs billions to take a new drug from discovery to market. DL technique has the potential to revolutionise this field of human endeavour.
Energy leaders (like BP and GE) use these techniques to improve performance, better use of resources, greater safety and more reliability of oil and gas production and refining. They use sensors that relay the conditions at each site to improve operations, and put data at the fingertips of engineers, scientists, and decision-makers. Some, like GE Power, use ML and DL, and “Internet of Things”(IoT) to build an “Internet of Energy (IoE).” Analytics enable predictive maintenance, operations, and business optimization to help achieve the vision of a “digital power plant.”
Credit Agencies (like Experian) get a large amount of data from market databases, transactional records and public information. They are embedding ML and DL into their products to allow for quicker and more effective decision-making. Trillions of dollars are processed (by the likes of American Express) in transactions with millions of cards. They rely heavily on data analytics and algorithms to help detect fraud in real time, thereby saving millions in losses.
Healthcare requires analysis of billions of CT and MRI scans and other records each year to look for signs of cancer and other serious diseases. This is a time-consuming and tedious process associated with errors. Vision-trained algorithms in ML and DL help radiologists to diagnose these problems more accurately, quickly, and efficiently.
Manufacturers are using data in ML to predict when vehicle parts would fail and when vehicles need servicing, thereby improving their performance during unforeseen situations. Companies like Volvo and BMW have big databases to guide decisions regarding design, engineering, and aftercare. They are also using ML technology in developing driverless vehicles. Some companies are getting data-driven analytical tools and automation for farming operations like pest control, ploughing and sowing with accurate GPS systems.
Media (like BBC and Amazon Echo) use ML to create better interactive programs with their audience. Press Associations are planning to employ robots and AI-based ML to save local news, and filling a gap in news coverage that is not being filled by humans. ML is helping them to predict what their customers will enjoy watching. Companies (like Walmart) are using ML to provide better services to their retail customers. They use ML and DL to understand the difference in behaviour of online and in-store customers. Google, Microsoft, and Disney are also using ML and DL.
A New Mathematical Idea that may reduce the dataset size needed to train AI systems has been proposed by statisticians at the University of Waterloo, in Canada. This allows for teaching AI systems without a large dataset. The system can learn with much less data because it is trained to recognize similar numbers or situations in a new way. They call these hints soft labels and have applied them to datasets describing XY coordinates on a graph. Thus, AI system can be trained to place dots on a graph on the correct side of a line drawn without the need for a large dataset.
………………………………………………………………………………………………………………………………………………………………………………..
Dr S. S. Bhatti was Formerly Professor & Head, Department of Physics, (Later, Applied Physics) and Dean (Sciences, later Applied Sciences), Guru Nanak Dev University, Amritsar. He was later the Director-Principal, Adesh Institute of Engineering & Technology, Faridkot, and Dean (Research), Akal University, Talwandi Sabo, Bathinda, all in Punjab (India). He is now in Canada.
………………………………………………………………………………………………………………………………………………………………………………….

excellent write up.. simple and comprehensive ..
LikeLike
Thank you, Dr. Rajbir Singh Bhatti for your comment.
LikeLike